偷拍自拍视频
发布日期:2024-11-05 21:00 点击次数:141

剪辑:LRST海外呦呦
【新智元导读】SegVG是一种新的视觉定位才能,通过将界限框疑望回荡为像素级分割信号来增强模子的监督信号,同期哄骗三重对都模块搞定特征域互异问题,提高了定位准确性。实验已矣流露,SegVG在多个规范数据集上卓绝了现存的最好模子,讲解注解了其在视觉定位任务中的灵验性和实用性。
视觉定位(Visual Grounding)旨在基于解放模式的当然说话文本抒发定位图像中的方向物体。
跟着多模态推理系统的普及,如视觉问答和图像刻画,视觉定位的进犯性更加突显。已有的相关约莫不错分为三类:两阶段才能、单阶段才能和基于Transformer的才能。
尽管这些才能取得了精采的恶果,但在疑望的哄骗上仍显得不及,尤其是仅将框疑望动作总结的真值样本,截至了模子的性能领悟。
具体而言,视觉定位靠近的挑战在于其寥落的监督信号,每对文本和图像仅提供一个界限框标签,与方向检测任务(Object Detection)存在权贵不同,因此充分哄骗框疑望至关进犯,将其视为分割掩膜(即界限框内的像素赋值为1,外部像素赋值为0),不错为视觉定位提供更细粒度的像素级监督。
伊利诺伊理工学院、中佛罗里达大学的相关东说念主员淡薄了一个名为SegVG的新才能,旨在将界限框级的疑望回荡为分割信号,以提供更为丰富的监督信号。

论文勾搭:https://arxiv.org/abs/2407.03200海外呦呦
代码勾搭:https://github.com/WeitaiKang/SegVG/tree/main
该才能看法多层多任务编码器-解码器结构,学习总结查询和多个分割查询,以通过总结和每个解码层的分割来杀青方向定位。
此外,为了搞定由于特征域不匹配而产生的互异,相关中引入了三重对⻬模块,通过三重细神思制更新查询、文本和视觉特征,以确保分享合并空间,从而提高后续的方向检测恶果。
综上,SegVG通过最大化界限框疑望的哄骗,提供了终点的像素级监督,并通过三重对⻬摒除特征之间的域互异,这在视觉定位任务中具有进犯的创新有趣。
以下是来自论文中的有关图示,用以进一步讲解视觉定位框架的不同:
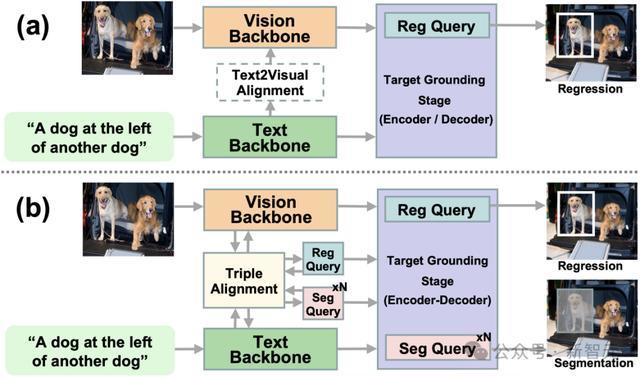
才能
在本节中,先容了SegVG才能的各个组件,按数据流的法例进行讲解,包括⻣干收罗、Triple Alignment模块以及Multi-layer Multi-task Encoder-Decoder。
⻣干收罗
SegVG才能的视觉⻣干收罗和文本⻣干收罗别离处理图像和文本数据。视觉⻣干收罗使用的是经过Object Detection任务在MSCOCO数据集上预历练的ResNet和DETR的Transformer编码器。
文本⻣干收罗使用BERT的镶嵌层将输入文本调节为说话Token,在Token前添加一个[CLS]秀丽,并在末尾添加一个[SEP]秀丽,随后通过BERT层迭代处理得到说话镶嵌。
Triple Alignment
Triple Alignment模块奋力于搞定视觉主干、文本主干和查询特征之间的域互异。该模块哄骗细心力机制推行三角形特征采样,确保查询、文本和视觉特征之间的一致性。
输⼊的查询被启动化为可学习的镶嵌,包含一个总结查询和多个分割查询。这⼀经过按以下方式进行:
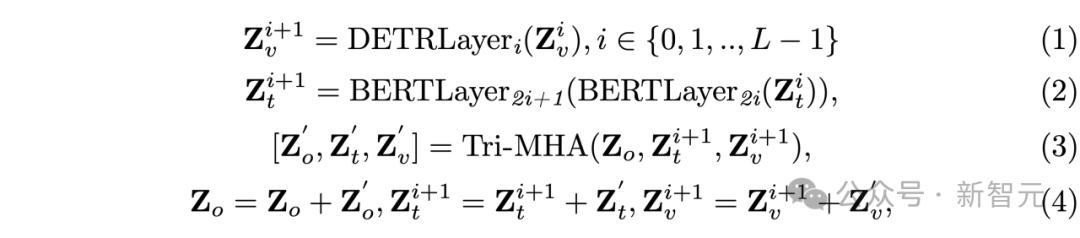
通过这种方式,Triple Alignment模块好像在每⼀层迭代匡助三类特征杀青存效地对都。
Multi-layer Multi-task Encoder-Decoder
其方向对接阶段的中枢部分,旨在通过跨模态和会和方向对接同期推行边框总结任务和边框分割任务。
编码器部分和会了文本和视觉特征,每一层通过多头自细心力层(MHSA)和前馈收罗(FFN)经过杀青提高。解码器部分则通过bbox2seg范式将边框疑望回荡为分割掩码,分割掩码将框内的像素秀丽为出路(值为1),而框外像素则秀丽为布景(值为0)。
在每一解码层中,一个总结查询用于总结边框,多个分割查询则用于对方向进行分割。
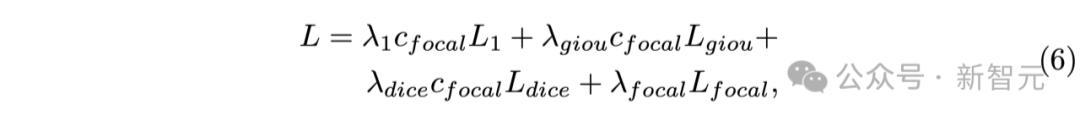
上述公式中,各式圆寂函数(如L1圆寂、GIoU圆寂、Focal损成仇Dice圆寂)被汇集用于驱动模子的历练经过,使得模子在推行总结和分割任务时得到强化的响应。
通过将分割输出的信心值回荡为Focal圆寂因子,不错灵验地强调那些难以历练的数据样本,以进一步提高模子的性能。
合座而言,SegVG才能杀青了对边框疑望的最大化哄骗,并灵验搞定了多模态特征间的域互异问题,为视觉方向定位任务带来了进犯的改良和提高。
实验
在实验部分,相关者对所淡薄的SegVG模子进行了全面的评估,触及多个规范数据集和不同的实验开荒,以考证其灵验性和优胜性。
狡计与数据集
相关者遴荐的主要评估狡计是交并比(IoU)和前1准确率,以评测度算界限框与确切界限框的匹配进程。使用的规范基准数据集包括RefCOCO、RefCOCO+、RefCOCOg-g、RefCOCOg-umd以及Refer It Game等。
实施细节
相关中对数据输入进行了相配设置,使用640x640的图像大小,以及最大文本⻓度设定为40。当图像大小调整时,会保抓原始宽高比。模子的历练经过遴荐AdamW优化器,过火学习率和权重衰减参数。
定量已矣
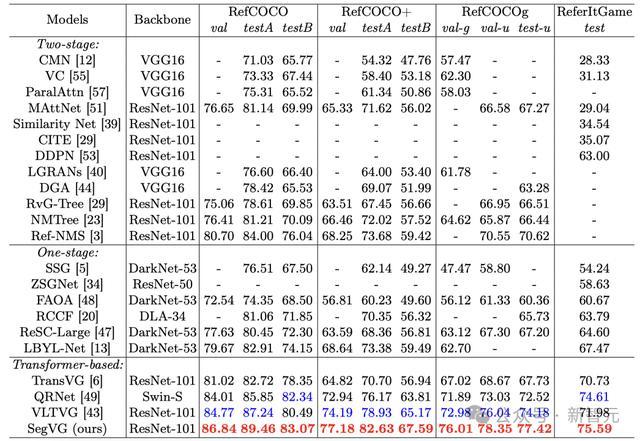
在定量实验中,SegVG模子在总共基准数据逼近领悟出色。举例,在RefCOCO+数据集上,其事前历练模子在各个子集上相较于之前的登程点进模子取得了权贵提高,别离达到了2.99%、3.7%和2.42%的准确率提高。
在RefCOCOg数据集上,SegVG一样取得了+3.03%、+2.31%和+3.24%的准确率提高。这些已矣讲解注解了汇集TripleAlignment和Multi-layerMulti-taskEncoder-Decoder后,模子在方向定位和准确性上的提高。
消融相关
进一步分析通过限度变量法对各个模块的灵验性进行消融相关。相关流露,加入Triple Alignment模块后,不错灵验摒除查询、文本及视觉特征之间的限制互异,进而促进后续的方向定位。
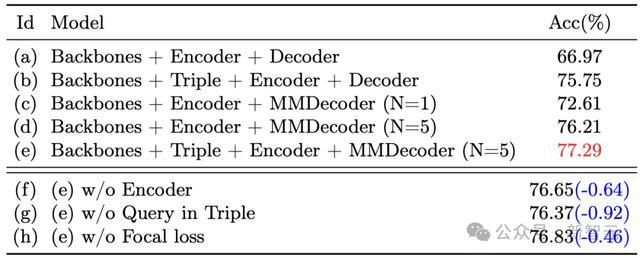
此外,通过加入Multi-layer Multi-task监督,好像迭代充分哄骗疑望信息,从而增强查询暗意的学习才调。
计较支出相比
相关者还对不同Transformer模子的参数数目和GFLOPS进行了相比,以评估SegVG的计较支出,已矣标明,SegVG的计较本钱处于合理范围,顺应实质应用需求。

定性已矣
在定性分析中,通过对比不同模子在方向检测中的领悟,SegVG在启动解码层阶段就能准确识别方向位置,相较于对比模子VLTVG而言,领悟更加正经。
国厂视频偷拍a在线
具体案例中,SegVG到手定位复杂布景下的方向,流露了其在多任务优化时的高度灵验性。
参考贵府:
https://arxiv.org/abs/2407.03200
Powered by 香蕉在线精品视频在线 @2013-2022 RSS地图 HTML地图
Copyright Powered by365站群 © 2013-2024
